우리 주변엔 많은 시계열 데이터가 존재한다.
당장 내 주변에만 해도 하루에 접하는 시계열 데이터는
서버 트래픽 데이터, 상품 구매 데이터, 유튜브 Studio 컨텐츠 시청 데이터, 주가 데이터 등이 있다.
이 중 주식데이터를 예측하는 모델을 만들어보기로 했다.
결론부터 말하자면 주식 가격은 아주 많은 요인들이 얽혀있는 데이터이기 때문에
만들 어진 모델로 주가를 예측하는 것은 아주 어렵다.
하지만 시계열 데이터를 분석하고 예측하는 모형에 대해 알아보고 공부하기 위함을 목적으로 둔다.
코드들은 TensorFlow의 학습 가이드를 참고하여 만들어진 코드들입니다.
https://www.tensorflow.org/learn
Finance Data Reader - 주식데이터 가져오기
일단 주가 데이터를 가져온다.
많은 사람들이 관심가지는 삼성전자 데이터를 준비하기로 했다.
# finance-datareader 다운로드
!pip install -U finance-datareader
import FinanceDataReader as fddr
import pandas as pd
from datetime import datetime
df = fdr.DataReader('005930')date_time = pd.to_datetime(df.index, format='%Y-%m-%d')
df = df.iloc[-380:]
import matplotlib.pyplot as plt
plt.grid(True)
plt.xticks(rotation=45)
plt.plot(df.Close, label='Close')
# column 의 인덱스와 이름을 관리하기 위한 dict 객체
column_indices = {name:i for i, name in enumerate(df.columns)}가져온 데이터는 아래와 같은 형태이다.

Data Scaling
다음으론 데이터 스케일링을 진행한다.

모델을 만들 때
모델을 특성의 숫자들을 보고 영향을 받는다.
특성들마다 고유한 범위가 존재할 수 있는데
이런 특성의 고유성을 무시한 채 단순히 크기 그 자체를 보고 해석할 수 있어 큰 값을 가지는 특성에 강하게 영향을 받을 수 있다.
그래서 특성별로 편향되지 않도록 모델을 형성하기 위해 scaling을 진행해야 한다.
크게 정규화와 표준화로 나뉠 수 있는데
정규화는 특성들의 범위를 제한하는데 큰 목적을 둔다.
가끔 특성들을 0~1까지 범위로 제한해서 백분율처럼 사용하고싶을때가 있다. 개인적으론 이럴 때 정규화를 사용하곤 헸다.
정규화는 특성들의 최소값과 최댓값을 통해 진행한다.
표준화는 특성들의 평균을 맞추는데 목적을 둔다.
정규화와는 다르게 데이터들의 범위는 다르지만
평균을 0 분산을 1로 맞추어 사용하고자 할 때 사용한다.
정규화와 다르게 특성들의 평균과 분산을 통해 계산된다.
이번 경우에는 표준화를 통해서 진행하기로 했다.
표준화와 정규화에 정답은 없다지만
정규화를 하는것이 데이터의 분포를 더 무시하고 0~1의 틀에 가둔다는 생각에
data loss가 더 발생하는 것이라 생각이 들었다.
데이터의 다양한 분포 또한 수치적이진 않지만 데이터에 담겨 있는 정보이고
모델이 이런 것들을 잘 잡아내고 이해하는지 확인해보고싶었다.
정규화를 통해 모델을 만들어보진 않아서 다음 기회에 해보기로..
그전에 전체 데이터를 train, test, validation 데이터로 나누었다.
# train, test, validation data split
n = len(df)
train_df = df[0:int(n * 0.7)]
val_df = df[int(n * 0.7):int(n * 0.9)]
test_df = df[int(n * 0.9):]
num_features = df.shape[1]
# Standardization
train_mean = train_df.mean()
train_std = train_df.std()
train_df = (train_df - train_mean) / train_std
val_df = (val_df - train_mean) / train_std
test_df = (test_df - train_mean) / train_std
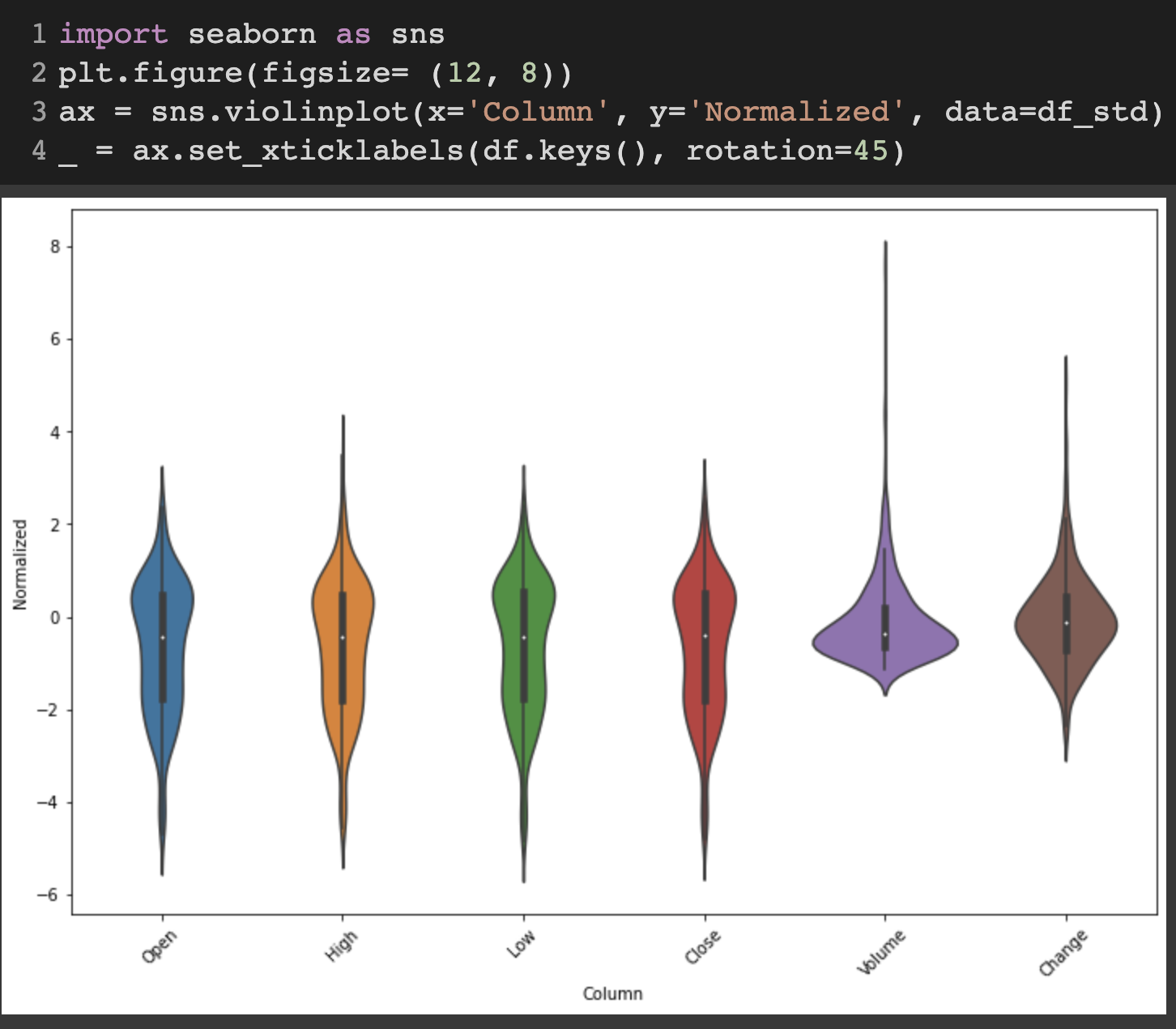
표준화를 시키고 시각화해보면 아래와 같다.
정규화를 통해 진행했다면 아래 보이는 이상치들로 인한 긴 꼬리를 많이 제거할 수 있었을 것 같은 생각이 든다.
Windowing
시계열이라는 말 자체에는 일정 시간 간격 상의 데이터라는 의미가 담겨있다.
일정 시간 간격을 하나의 창으로 보고
창들의 연속된 집합을 시계열 데이터로 설명하고 도식화한 개념으로 이해했다.

위의 사진처럼 t는 시간을 의미하고 1씩 증가시마다 시계열 데이터의 일정 간격씩 시간이 증가함을 의미한다.
모델이 데이터를 받아들이고 값을 예측해나갈 때 시계열 데이터를 이런 Window 객체로 받아들여
모델 제작에 도움을 주기 위한 객체를 만든다.
WindowGenerator는 train/val/test 데이터를 구분하고
특성의 이름, 우리가 예측하고자 하는 label column(여기서는 미래의 주식 종가(Close))
입력받는 input window width, label width(1 day, 10 day 등) 들을 선언해주고
데이터들을 나눈다던가 시각화하거나 모델 측으로 전달하기 위해 전처리, getter, setter 함수들을 만들어주었다.
import numpy as np
class WindowGenerator():
def __init__(self, input_width, label_width, shift, train_df=train_df, val_df=val_df, test_df=test_df,
label_columns=None):
self.train_df = train_df
self.test_df = test_df
self.val_df = val_df
# work out the label column indices.
self.label_columns = label_columns
if label_columns is not None:
self.label_columns_indices = {name: i for i, name in enumerate(label_columns)}
self.column_indices = {name: i for i, name in enumerate(train_df.columns)}
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width)
self.input_indices = np.arange(self.total_window_size)[self.input_slice]
self.label_start = self.total_window_size - self.label_width
self.labels_slice = slice(self.label_start, None)
self.label_indices = np.arange(self.total_window_size)[self.labels_slice]
def __repr__(self):
return '\n'.join([
f'Total window size: {self.total_window_size}',
f'Input indices: {self.input_indices}',
f'Label indices: {self.label_indices}',
f'Label column name(s): {self.label_columns}'
])
def split_window(self, features):
inputs = features[:, self.input_slice, :]
labels = features[:, self.labels_slice, :]
if self.label_columns is not None:
labels = tf.stack([labels[:, :, self.column_indices[name]] for name in self.label_columns], axis=-1)
inputs.set_shape([None, self.input_width, None])
labels.set_shape([None, self.label_width, None])
return inputs, labels
def plot(self, model=None, plot_col='Close', max_subplots=3):
inputs, labels = self.example
plt.figure(figsize=(12, 8))
plot_col_index = self.column_indices[plot_col]
max_n = min(max_subplots, len(inputs))
for n in range(max_n):
plt.subplot(max_n, 1, n + 1)
plt.ylabel(f'{plot_col} [normed]')
if self.label_columns:
label_col_index = self.label_columns_indices.get(plot_col, None)
else:
label_col_index = plot_col_index
if label_col_index is None:
continue
plt.plot(train_df[100 * n:100 * n + self.total_window_size - self.shift].index,
inputs[n, :, plot_col_index],
label='Inputs',
marker='.', zorder=-10, )
plt.scatter(
train_df[100 * n + self.total_window_size - self.label_width:100 * n + self.total_window_size].index,
labels[n, :, label_col_index], edgecolors='k',
label='Labels', c='#2ca02c', s=64)
if model is not None:
# plt.axvline(x=train_df.index[100 * n + self.total_window_size - 1], color='r', linestyle='--')
# plt.axvspan(train_df.index[100 * n + self.total_window_size - 1], train_df.index[100 * n + self.total_window_size], facecolor='yellow', alpha=0.3)
predictions = model(inputs)
plt.scatter(train_df[100 * n + self.total_window_size - self.label_width:100 * n + self.total_window_size].index, predictions[n, :, label_col_index],
marker='X', edgecolors='k', label='Predictions', c='#ff7f0e', s=64)
if n == 0:
plt.legend()
plt.xlabel('Time [h]')
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds = tf.keras.preprocessing.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=self.total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=32, )
ds = ds.map(self.split_window)
return ds@property
def train(self):
return self.make_dataset(self.train_df)
@property
def val(self):
return self.make_dataset(self.val_df)
@property
def test(self):
return self.make_dataset(self.test_df)
@property
def example(self):
"""Get and cache an example batch of `inputs, labels` for plotting."""
result = getattr(self, '_example', None)
if result is None:
# No example batch was found, so get one from the `.train` dataset
result = next(iter(self.train))
# And cache it for next time
self._example = result
return result
WindowGenerator.train = train
WindowGenerator.val = val
WindowGenerator.test = test
WindowGenerator.example = example
WindowGenerator 객체를 만들기 위해
input_width : 입력으로 쓰일 기간
label_width : 예측 label의 크기 기간
shift : input_width + shift 만큼의 위치를 예측
ex) input으로 1월 1일 1월 2일... -> shift 1일 경우 1월 2일, 1월 3일 예측
import tensorflow as tf
w1 = WindowGenerator(input_width=24, label_width=1, shift=24, label_columns=['Close'])
w2 = WindowGenerator(input_width=6, label_width=1, shift=1, label_columns=['Close'])
example_window = tf.stack([np.array(train_df[:w1.total_window_size]),
np.array(train_df[100:100+w1.total_window_size]),
np.array(train_df[200:200+w1.total_window_size])])
example_inputs, example_labels = w1.split_window(example_window)
print('All shapes are: (batch, time, features)')
print(f'Window shape: {example_window.shape}')
print(f'Inputs shape: {example_inputs.shape}')
print(f'labels shape: {example_labels.shape}')
w1.example = example_inputs, example_labels
w1.plot()
w2.example = example_inputs, example_labels
w2.plot()
앞으로 만들 모델에서 아래 window 객체를 많이 사용할 예정이다.
24일 범위의 연속 입력과 레이블을 생성하는 windw window generator를 만들었다.
shift=1으로 입력을 받고 다음 1일 뒤의 미래를 예측한다.
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1,
label_columns=['Close']
)
BaseLine Model

기준선 모델은 우리가 모델을 만들 때 기준이 되는 척도로 사용될 모델이다.
t=1의 예측값으로 t=0을 제시하는 간단한 로직으로만 이루어진 모델이다.
예를 들어 1월 2일의 값 예측으로 1월 1일의 종가만 제시하는 모델이다.
하지만 많은 노력을 들인 모델도 이런 간단한 모델도 이기지 못하는 경우가 많이 발생한다.
#Baseline model 클래스 선언
class Baseline(tf.keras.Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
if self.label_index is None:
return inputs
result = inputs[:, :, self.label_index]
return result[:, :, tf.newaxis]
# Baseline 모델을 통해 wide_window 데이터를 예측해본 결과
baseline = Baseline(label_index=column_indices['Close'])
baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
val_performance = {}
performance = {}
val_performance['Baseline'] = baseline.evaluate(wide_window.val)
performance['Baseline'] = baseline.evaluate(wide_window.test, verbose=2)
wide_window.plot(baseline)
Linear Model

# 기본적인 선형모델을 만들어준다.
linear = tf.keras.Sequential([
tf.keras.layers.Dense(units=1)
])
# 앞으로 만들 모델들을 compile, fit 하기 위한 함수를 선언하고 호출하고 결과를 기록한다.
MAX_EPOCHS = 20
def compile_and_fit(model, window, patience=2):
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=patience, mode='min')
model.compile(loss=tf.losses.MeanSquaredError(), optimizer =tf.optimizers.Adam(), metrics=[tf.metrics.MeanAbsoluteError()])
history = model.fit(window.train, epochs=MAX_EPOCHS, validation_data = window.val, callbacks=[early_stopping])
return history
history = compile_and_fit(linear, wide_window)
val_performance['Linear'] = linear.evaluate(wide_window.val)
performance['Linear'] = linear.evaluate(wide_window.test, verbose=0)
wide_window.plot(linear)
DNN
dense = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=1)
])
history = compile_and_fit(dense, wide_window)
val_performance['Dense'] = dense.evaluate(wide_window.val)
performance['Dense'] = dense.evaluate(wide_window.test, verbose=0)
wide_window.plot(dense)
Multi-step Dense

1개의 입력을 받아서
모델에 바로 처리하는 기존의 Dense 모델에서는
시간의 흐름에 따라 입력 특성이 어떻게 변하는지 모델이 알 수 없다.
시계열에서 그런 흐름상 패턴을 찾아낼 수 도 있기 때문에 Multi-step Dense 모델을 만든다.
CONV_WIDTH = 3
conv_window = WindowGenerator(
input_width=CONV_WIDTH,
label_width=1,
shift=1,
label_columns=['Close']
)multi_step_dense = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1),
# 출력을 (1, outputs)로 유지하기 위한 Reshape
tf.keras.layers.Reshape([1, -1])
])
history = compile_and_fit(multi_step_dense, conv_window)
val_performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.val)
performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.test, verbose=0)
conv_window.plot(multi_step_dense)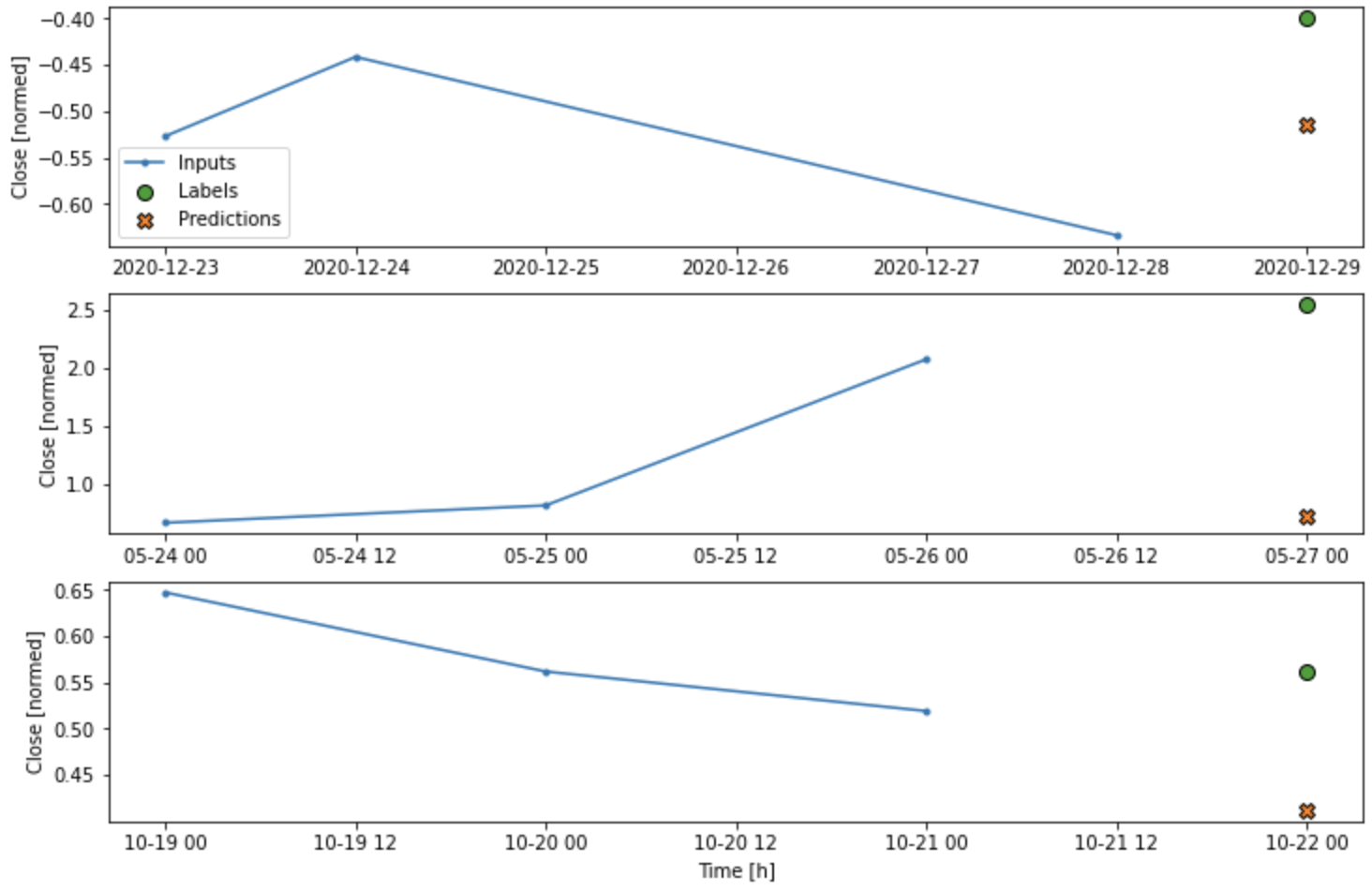
위 그래프를 봐서는 다음 구간에 대한 예측을 미리 보지 못한다.
multi-step dense model의 단점은 입력 3구간에 대한 1개의 다음 구간 예측 형상에만 실행된다는 단점이 있다.
wide_window에 multi_step_dense 모델을 넣고 ploting 하면 에러가 발생할 것이다.
CNN

CNN을 통해서는 여러 타임 스텝을 입력받아 모델로 처리 가능하다.
conv_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=(CONV_WIDTH,), activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1)
])
print("Conv model on `conv_window`")
print('Input shape:', conv_window.example[0].shape)
print('Output shape:', conv_model(conv_window.example[0]).shape)
history = compile_and_fit(conv_model, conv_window)
val_performance['Conv'] = conv_model.evaluate(conv_window.val)
performance['Conv'] = conv_model.evaluate(conv_window.test, verbose=0)대신 Labels에 대한 처리를 해주기 위해 Window객체를 다시 만들어주었다.
LABEL_WIDTH = 24
INPUT_WIDTH = LABEL_WIDTH + (CONV_WIDTH - 1)
wide_conv_window = WindowGenerator(
input_width=INPUT_WIDTH,
label_width=LABEL_WIDTH,
shift=1,
label_columns=['Close'])
wide_conv_window.plot(conv_model)
RNN

RNN은 시계열 데이터에 적합한 신경망 유형이다.
시계열을 단계적으로 처리하면서도 처리된 모델의 결과를 다음 모델에 순환적으로 적용한다.
warmup은 최종 타임 스텝의 출력만 반환하여 수행전 모델이 내부 상태를 준비할 시간을 준다.

return_sequences=True로 설정하면 각 타임 스텝에서 모델에 대한 출력을 predictions에 반환하는데
RNN 레이어를 쌓거나 여러 타임스텝에서 동시에 모델을 훈련하는 경우 유용하다.
RNN에 대한 구현과 자세한 내용은 추후에 더 공부를 해볼 예정이다.
이번 RNN모델에서는 LSTM 모델을 사용할 예정이다.
lstm_model = tf.keras.Sequential([
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.Dense(units=1)
])
history = compile_and_fit(lstm_model, wide_window)
val_performance['LSTM'] = lstm_model.evaluate(wide_window.val)
performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0)
wide_window.plot(lstm_model)
Performance

지금까지 구현한 모델들의 성능을 비교해 본다.
그래프의 높이는 Mean Absolute Error를 나타내며 적을수록 우수한 모델이다.
역시나 가장 간단한 Baseline model보다 나은 모델이 거의 없다.
아직 Single-shot models에 대해서 다루지 않았지만 다음 글을 통해 다룰 예정이다.
'Data & AI' 카테고리의 다른 글
| [강화학습] 2. 강화학습은 인생이다. (0) | 2023.02.20 |
|---|---|
| [강화학습] 1. 소개 (0) | 2023.02.13 |
| [Data] 1월 주식 데이터 분석과 인공지능의 필요성 (0) | 2023.02.01 |
| [Data] 암호화폐 데이터 처리 - 자동투자를 위한 전략 signal score feature 가공 (0) | 2022.12.05 |
| [Airflow] Docker Compose 기반 Airflow 구성과 주식 메타데이터 추출과 적재 (1) | 2022.09.18 |



