암호화폐 알고리즘 투자 코드에 대한 설명이 필요할 것 같아서
기본적으로 제공받는 데이터에서 어떤 가공을 통해 feature들을 만들어내는지 공개하려고 한다.
데이터 준비
요즘 암호화폐 거래소에 대한 불신이 깊어지면서
원래도 binance에서 제공받은 api를 통해 매매하고 있었고
그래도 1위 거래소인 binance를 통해 계속 알고리즘을 구동시키려고 한다.
(어느 정도 암호화폐 거래소에 대한 신뢰가 쌓이기 전까지는 알고리즘 투자에 사용되는 비용을 좀 줄여서 운용하고 있다.)
binance에서는 python에서 사용하기 쉽도록 라이브러리를 제공하고 있다.
그리고 ccxt라는 파이썬 라이브러리도 거래소의 기능들을 손쉽게 사용할 수 있어서 같이 사용하곤 한다.
api key를 발급받는 과정도 계정 인증만 잘 되어있다면 홈페이지에서 간단하게 발급받을 수 있다.
아래는 해당 라이브러리들을 사용해서 이더리움의 가격 데이터를 조회하고 있다.
알고리즘이 선물거래를 하기 때문에 future option도 준다.
key = ''
s_key = ''
binance = ccxt.binance(config={
'apiKey': key,
'secret': s_key,
'enableRateLimit': True,
'options': {
'defaultType': 'future'
}
})
SYMBOL = 'ETHUSDT'
btc = binance.fetch_ohlcv(
symbol=SYMBOL,
timeframe='1d',
since=None,
limit=100)
df = pd.DataFrame(btc, columns=['datetime', 'open', 'high', 'low', 'close', 'volume'])
이건 라이브러리를 통해 거래소에서 받은 데이터 원본이다.
datetime을 보면 int의 timestamp로 되어있는데 우리가 알아보기 쉽도록 datetime으로 변경한다.
df['datetime'] = pd.to_datetime(df['datetime'], unit='ms')
df.dtypes
알고리즘 signal feature를 가공하기 전에
내가 운용하는 알고리즘 트레이딩 시스템에서는 두 가지 개념이 들어가 있다.
- 의미 있는 전략들은 각자 강한 시기가 있다. (흔히 잘 먹히는 구간이라고 한다)
- 자산들의 리밸런싱을 통해 통계적 비선형 구조를 얻는다.
두 번째 개념을 추가로 설명하자면
레이달리오의 all-weather 전략은
경제에 필요한 자산군을 배치하고 주기별로 리밸런싱 하면서
초기 정했던 자산군별 비율을 유지한다.
리밸런싱 하는 과정에 자연스럽게 상승한 자산을 수익을 보고 일부 매도하고
하락한 자산을 저렴한 가격에 추가 매수하는 구조로
긴 기간 동안 통계적으로 주기적인 비선형을 만들어낸다.
(물론 자산군을 어떻게 형성하느냐에 따라 선택한 자산이 모두 하락한다면 이야기가 다르다.)
해당 전략이 통계적으로 절대 우위에 설 수 있는 건
경제적으로 유의미한 자산군을 선정하고
해당 자산들을 리밸런싱 했기 때문이다.
투자 전략 선정
여러 퀀트 전략들이 있고
운용 시 여러 전략들이 섞여 있지만
여러 전략들의 근간이 되는 건 아래 두 가지 전략이다.
- 추세추종 : 가격이 지속적으로 상승하는 '추세'라면 해당 자산을 매수하여 추가적인 추세를 기대하는 전략
- 역추세추종 : 가격이 추세를 보이다가 변동될 것이라는 기대로 추세에 반하는 구간에 진입하여 수익을 기대하는 전략
놀랍게도 두 가지 전략은 상반되는 전략이지만
모두 여러 자산시장에 유의미한 전략이다.
아래를보면 상반되는 두 전략이
둘 다 잘먹히는 구간, 한 전략만 잘 먹히는 구간 등이 눈에 보인다.
하지만 장기적으로는 유의미한 투자 수익을 얻을 수 있다.
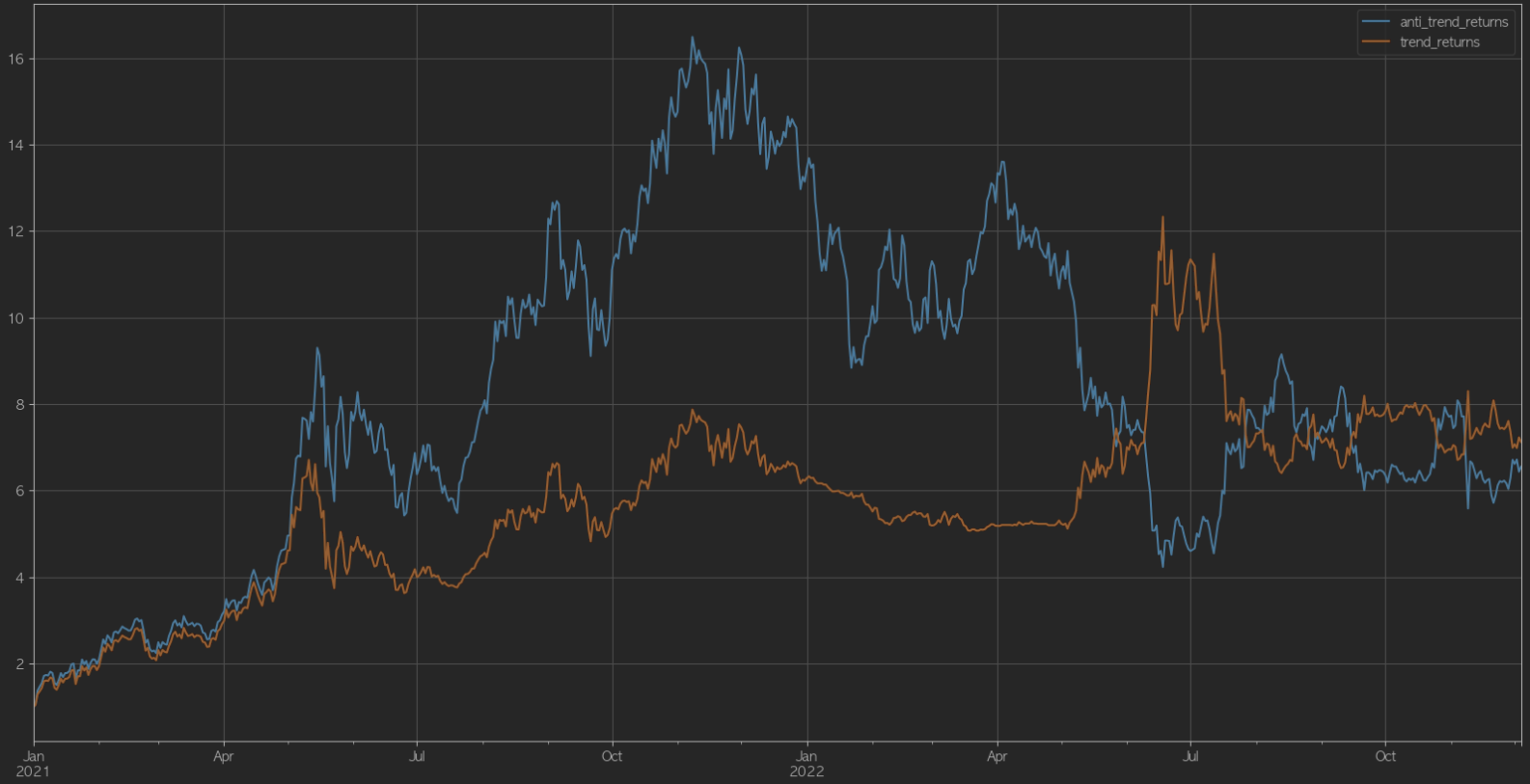
레이달리오는 시장에 존재하는 여러 자산군들을 포트폴리오에 편입했다.
이 자산군들은 경제 상황에 따라 언젠가는 힘을 얻는 자산들이다.
금, 달러(현금), 주식, 채권, 원자재 등이 있다.
여러 투자자들의 책을 보면서 시장에는 여러 전략이 존재하고
서로 상반되는 전략임에도 언젠가는 힘을 얻는 전략들이 있다.
여기에 아이디어를 얻어서 투자에 적용되는 알고리즘들의 포지션을 일정 비율로 유지하여
주기적으로 리밸런싱 하는 것이 나의 투자 알고리즘의 핵심이다.
이 과정에서 수익을 낸 전략의 포지션을 덜어내어 수익을 실현하고
자연스럽게 지금은 시기적으로 성과를 내지 못했지만 미래에 성과를 낼 전략에 추가 포지션을 넣으면서
투자 전략의 DrawDown 지점에서 추가 매수를 할 수 있다.
전략들의 feature 생성
추세추종 전략의 feature
추세추종 전략은 내가 접한 전략 중 어쩌면 가장 간단하지만 결국 인간의 심리로 만들어지는 시장을 잘 간파하고 있다.
보통 과거 시점의 가격보다 현재 시점의 가격이 상승중이라면 매수, 하락중이라면 매도를 하는데
그 과거시점의 기간은 자산군, 어느 시장이냐에 따라 차이가 있어서
나는 여러 시점의 데이터를 참고해서 포지셔닝한다.
PERIOD = 10
df['returns'] = df['close'].pct_change()
df['trend_10'] = np.where(df['close'].shift(PERIOD * 1) < df['close'], 1, -1)
df['trend_20'] = np.where(df['close'].shift(PERIOD * 2) < df['close'], 1, -1)
df['trend_30'] = np.where(df['close'].shift(PERIOD * 3) < df['close'], 1, -1)
df['trend_40'] = np.where(df['close'].shift(PERIOD * 4) < df['close'], 1, -1)
df['trend_50'] = np.where(df['close'].shift(PERIOD * 5) < df['close'], 1, -1)
df['trend_60'] = np.where(df['close'].shift(PERIOD * 6) < df['close'], 1, -1)
df['trend_70'] = np.where(df['close'].shift(PERIOD * 7) < df['close'], 1, -1)
df['trend_80'] = np.where(df['close'].shift(PERIOD * 8) < df['close'], 1, -1)
df['trend_90'] = np.where(df['close'].shift(PERIOD * 9) < df['close'], 1, -1)
df['trend_100'] = np.where(df['close'].shift(PERIOD * 10) < df['close'], 1, -1)
df['trend_score'] = (df['trend_10'] + df['trend_20'] + df['trend_30'] + df['trend_40'] + df['trend_50'] + df['trend_60'] + df['trend_70'] + df['trend_80'] + df['trend_90'] + df['trend_100'] )/ 10
df['trend_returns'] = df['returns'] * df['trend_score'].shift(1)trend 기간별로 매수할지(1) 매도할지(-1) 정하고
각 수치들의 평균을 구하면 -1, 1 사이의 수가 나온다. 이를 trend_score로 둔다.
우리는 이 trend_score를 보면서 매수의 강도를 조절한다.
trend_score는 오늘의 종가(df.close)를 보고 결정 난다.
그래서 D-day 종가가 결정이 나고 -> 포지셔닝을 바꾸고(D-day trend_score 생성) -> D+1 day returns와 D-day의 trend_score를 곱해서 수익률을 나타내야 한다.
이 부분에서 퀀트 입문, 심지어 유튜브 가장 큰 퀀트 채널에서 라이브 백테스트를 하면서 Look ahead bias를 범하고 있다.
이 실수를 해석해보면
오늘의 종가가 어떻게 될지 알고 포지셔닝을 하는 것이다.
특히 추세추종의 경우 오늘 가격이 오르는 것을 보고 어제 진입을 정하도록 백테스트가 되는 것이다.
이 점을 실수하게 되면 수익률이 극대화되고 실제 투자를 하면 기대 수익률보다 훨씬 적은 수익률을 얻게 된다.
그래서 trend_returns를 구할 때는 시장수익률(df ['returns'])과 어제 구한 trend_score(df ['trend_score']. shift(1)) 해야 한다.
역추세 전략의 feature
역추세 전략은 가격이 결국 평균에 회귀할 것이라고 기대하는 것이다.
이 전략도 논리적으로 타당한 근거를 가지고 수행되는 전략이고 과거 데이터도 유의미하다.
역추세 전략을 위해선 가격의 이동평균과 가격의 이격도를 feature로 뽑아두고 시각화를 해본다.
df['ma'] = df['close'].rolling(PERIOD).mean()
df['distance'] = df['close'] - df['ma']
df.distance.dropna().plot(figsize=(10, 6), legend=True)
plt.grid(True)
plt.axhline(0, color='r')
이더리움의 이격도를 출력해보았는데 거래량이 활발해지면서 이격도도 변동폭이 큰 것을 확인할 수 있다.
이격도에서 어느 정도를 벗어나면 평균에 회귀할 전략이 발동할지 정해야 하는데 이 부분을 `THRESHOLD`라고 정의했다.
이 threshold는 자산군, 시기마다 적절히 선택해야 하는 부분인 것 같다. 그냥 700 정도로 설정을 했다.
역추세 전략은 이격도가 너무 벌어지면 그 이격이 좁아질 것을 기대하면서 포지션을 진입하게 된다.
df['anti_trend_position'] = np.where(df['distance'] > THRESHOLD, -1, np.nan)
df['anti_trend_position'] = np.where(df['distance'] < THRESHOLD, 1, df['anti_trend_position'])
df['anti_trend_returns'] = df['returns'] * df['anti_trend_position'].shift(1)실제 알고리즘 투자에서는 trend_score, anti_trend_position 등에서
데이터를 더 첨가하고 응용해서 각 전략의 score를 통해 투입 자산을 정하고 있다.
지금 전략은 전통적인 퀀트 전략들과 기법들을 이용해서만 진행되고 있고
데이터를 더 활용하고 머신러닝 기법들과 강화 학습을 통해
우리가 임의로 정하고 있는 수치들을 더 유의미한 수치로 적용해보려고 노력하고 있다.
'Data & AI' 카테고리의 다른 글
| [강화학습] 2. 강화학습은 인생이다. (0) | 2023.02.20 |
|---|---|
| [강화학습] 1. 소개 (1) | 2023.02.13 |
| [Data] 1월 주식 데이터 분석과 인공지능의 필요성 (0) | 2023.02.01 |
| [Airflow] Docker Compose 기반 Airflow 구성과 주식 메타데이터 추출과 적재 (5) | 2022.09.18 |
| [AI] Timeseries - 삼성전자 주가예측 (1) | 2022.07.10 |



