트레이딩을 위한, 강화학습을 위한, 합성데이터를 위한, GAN을 위한..
안녕하세요.
오늘은 강화학습으로 트레이딩 모델을 훈련시키다가
필요하게 되어 시작된 작은 연구들을 조금씩 이야기해보려고 합니다.
강화학습 트레이딩
제가 서비스에 제공하는 모델들은 주로 현재 자산시장의 가격들의 예측을 하는 예측모델들이 주를 이룹니다.
예측모델들의 예측치를 보고 고객들이 가지고 있는 배경지식과 융합해서 투자의사결정을 도울 수 있는 데이터로
활용되길 원했기 때문인데요.
(물론 예측모델 자체로도 예측치가 상승이면 매수, 하락하면 매도.. 와 같은 간단한 전략으로 써도 되겠지만)
투자 의사결정을 돕는 가격 예측모델말고, 실제 트레이딩을 수행하는 모델들도 운용을 하고 있고
더욱 강력하게 훈련시키고자 하는 욕심이 있습니다.
제가 예전에도 강화학습 트레이딩에 대해 설명한 적 있긴 하지만.
트레이더들이 강화학습 개념을 처음 접하면 트레이딩에 잘 활용할 수 있을 것 같은 느낌이 듭니다.
에이전트라는 게 시장에서 행동(매수, 매도에 대한 포지션 결정)을 취하고,
그에 따라 보상을 받으면서 최적의 전략을 학습한다는 그림이 머릿속에 그려지니까요.
벨만 방정식은 기본적으로 상태 행동 그리고 그 결과로 전이되는 다음 상태를 기반으로 미래 보상을 추정합니다.
트레이딩을 생각해 보면 내가 취하는 행동이 직접적으로 시장의 수익률 데이터, 즉 상태를 변화하는 구조가 아닙니다.
시장은 나라는 개별 트레이더의 행동과 상관없이 자본주의에서 발생하는 많은 요소들에 의해 움직입니다.
물론 아주 큰 기관 투자자라면 모를까, 일반적인 트레이딩 환경에선 행동이 상태 전이를 주도한다고 보긴 어렵습니다.
그러다 보니 행동-상태 전이 함수를 학습하는 전통적인 강화학습 방식이 트레이딩에 꼭 들어맞는다고 보긴 어렵습니다.
대신, 우리가 상태라고 정의할 수 있는 가격 변동 데이터들에 주목했고
시장에서 발생하는 이벤트와 시간에 따라 변화하는 패턴을 가지고 있고
객관화할 수 있는 패턴들을 쌓아나가고 활용할 수 있다면 행동과 상태에 대한 전이는 정복하지 못하지만
상태 자체의 전이 확률에 대해선 어느 정도 근사할 수 있고, 그 함수를 보고 행동을 취하는 방식으로 연구를 해보고 있습니다.
더 많은 데이터
연구방향이 그렇다 보니 연구를 진행하는 방향은 합성데이터입니다.
트레이딩과 같은 시계열 영역에선 데이터가 한정적이라는 단점이 있습니다.
특정 자산과 종목마다 가지는 특성들이 다르기 때문에 Foundation Model 학습이나 학습할 데이터가 제한되게 됩니다.
강화학습은 사실 더 많은 데이터가 요구됩니다.
트레이딩 에이전트가 트레이딩 환경에서 여러 행동과 보상 데이터들을 쌓아나가는 게임을
무한히 반복해야 하는데 데이터 자체가 제한되기 때문입니다.
물론 저는 Offline 강화학습 방식을 적용하려고 하고 있어서 에이전트 모델이 직접 트레이딩을 하면서 학습하는 것은 아니지만
데이터가 다양하고 많아야 하는 건 여전히 중요합니다.
아무리 그래도 우리의 돈을 책임지는 트레이딩모델을 가짜 데이터로 학습시키는 게 말이 되는가 라는 의문을 가지실 수 있겠지만
이미 세상은 많은 연구자들이 직면한 문제를 해결하기 위해 연구를 하고 있고
저희는(저는) 그런 지식의 열매를 따서 일상에 직면한 문제를 해결하거나, 사업화를 해서 부가가치를 창출하면 됩니다.
물론 그런 것들을 이해하고 응용할 수 있는 수준이 필요합니다.
모든 분야이건 그런 기술을 이해할 수 있는 지식과 수준이 된다는 건 인생을 더욱 쉽게 해 줄 수 있는 시야를 주는 것 같습니다.
그래서 부모님이 늘 공부를 하라고..
합성 데이터와 GAN
그러한 결과로 InfoBoost라는 논문에서 (https://arxiv.org/pdf/2402.00607)
합성데이터만을 훈련된 모델이 실제 데이터로 훈련된 모델을 능가하는 경우를 보고했습니다.
다중 소스 리듬 신호와 노이즈를 포함하여 복잡한 시계열을 합성데이터로 재현했고
재구성하는 성능에서 우수성을 입증했습니다.

TimeGAN 은 GAN을 활용해 시계열 데이터를 생성하는 모델로
논문이 발표될 때부터 실제 주식 가격 데이터를 포함한 시계열 데이터에서 테스트되었고
이 연구는 합성데이터가 실제 데이터의 시간적 상관관계와 분포를 잘 모사하여
합성데이터로 훈련된 예측모델이 실제 데이터로 훈련된 모델과 비슷한 성능을 보였다고 합니다.
시계열의 Long-term memory를 보존한다는 점에서 큰 주목을 받기도 했습니다.
GAN 손실함수
위 시계열 합성데이터 형성을 위해 TimeGAN 논문의 코드를 살펴보았습니다.
# Discriminator loss
D_loss_real = tf.losses.sigmoid_cross_entropy(tf.ones_like(Y_real), Y_real)
D_loss_fake = tf.losses.sigmoid_cross_entropy(tf.zeros_like(Y_fake), Y_fake)
D_loss_fake_e = tf.losses.sigmoid_cross_entropy(tf.zeros_like(Y_fake_e), Y_fake_e)
D_loss = D_loss_real + D_loss_fake + gamma * D_loss_fake_e
# Generator loss
# 1. Adversarial loss
G_loss_U = tf.losses.sigmoid_cross_entropy(tf.ones_like(Y_fake), Y_fake)
G_loss_U_e = tf.losses.sigmoid_cross_entropy(tf.ones_like(Y_fake_e), Y_fake_e)
# 2. Supervised loss
G_loss_S = tf.losses.mean_squared_error(H[:,1:,:], H_hat_supervise[:,:-1,:])
# 3. Two Momments
G_loss_V1 = tf.reduce_mean(tf.abs(tf.sqrt(tf.nn.moments(X_hat,[0])[1] + 1e-6) - tf.sqrt(tf.nn.moments(X,[0])[1] + 1e-6)))
G_loss_V2 = tf.reduce_mean(tf.abs((tf.nn.moments(X_hat,[0])[0]) - (tf.nn.moments(X,[0])[0])))
G_loss_V = G_loss_V1 + G_loss_V2
# 4. Summation
G_loss = G_loss_U + gamma * G_loss_U_e + 100 * tf.sqrt(G_loss_S) + 100*G_loss_V
GAN은 위에서 대략적으로 설명했던
생성자(Generator)와 판별자(Discriminator)가 존재합니다.
1번은 판별자의 손실인데 실제데이터와 합성데이터를 구분하는 역할을 합니다.
손실함수는 Binary Cross Entropy를 사용합니다.
2번은 Generator loss인데 판별자를 속이고 실제 데이터와 유사한 합성데이터를 만들기 위해 여러 손실로 학습됩니다.
Adversarial loss, Supervised loss, Moment Matching loss 들을 적절히 조합해서 사용합니다.
- gamma: 임베딩 손실의 가중치.
- 100 * tf.sqrt(G_loss_S): 감독 손실에 큰 가중치(100)를 주고, 제곱근으로 스케일 조정.
- 100 * G_loss_V: 모멘트 손실에도 큰 가중치로 통계적 유사성 강조.
embedding을 위한 모델이나 supervisor, generator은 간단한 Layer들로만 계층을 쌓아서 학습을 진행시켜 보았습니다.
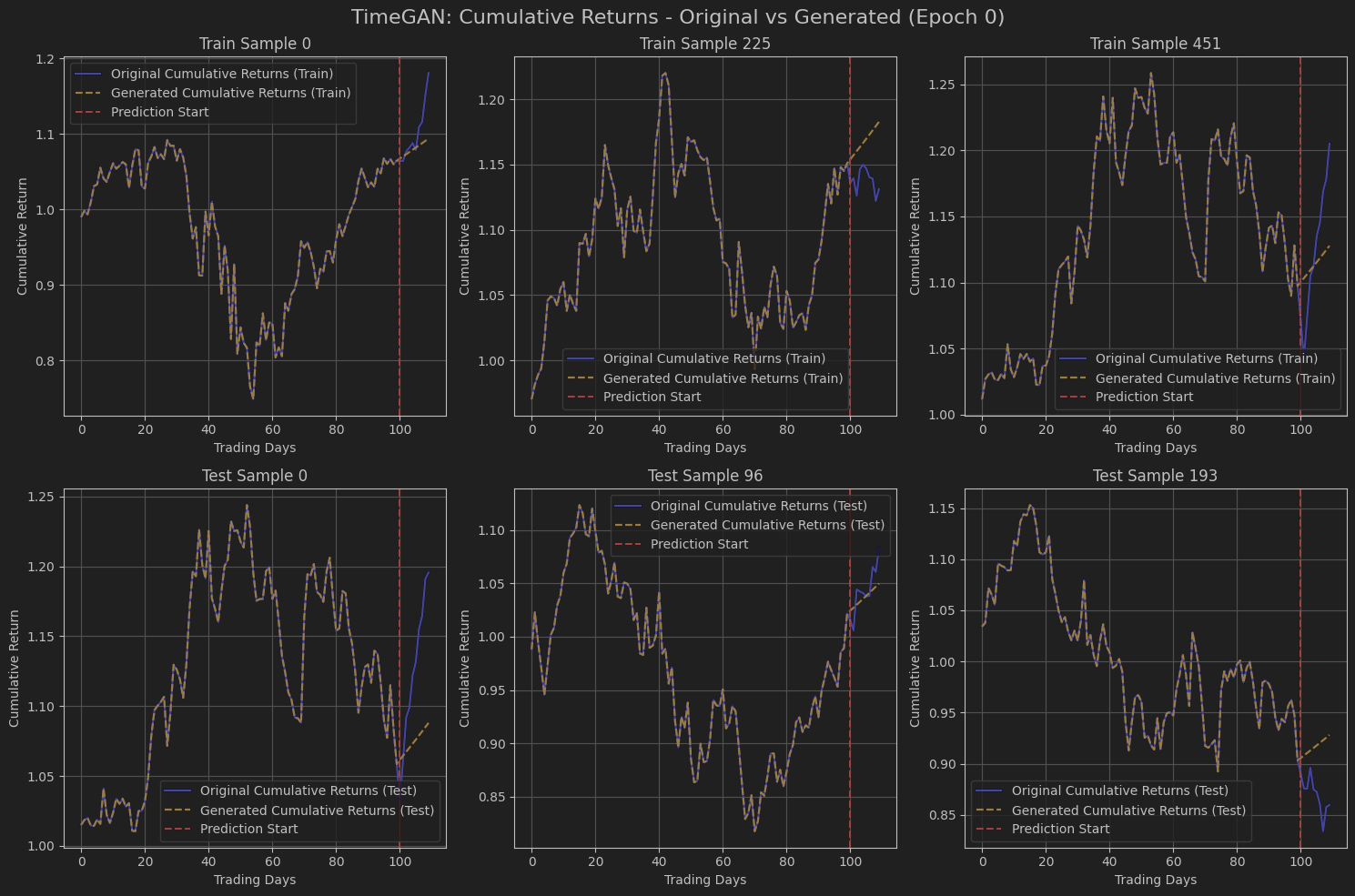
위는 학습에 대한 데이터들을 시각화해보았고
1행 데이터들은 학습데이터, 2행 데이터들은 테스트 데이터들입니다.
학습 전에는 입력에 대해 그냥 일정한 데이터들을 만들어내는지
생성 수익률들의 누적값(빨간 점선 기준 우측 주황점선)들이 일정하게 상승하고, 입력마다 동일합니다.
실제 데이터(파란색과 보라색 그 사이..)와 비교해 보면 큰 차이가 나오는 걸 확인할 수 있습니다.

어느 정도 학습을 진행하면 학습데이터에 대해선 당연히 fit하게 생성을 해내게 되고
테스트 데이터를 보더라도 입력에 대해 어느정도 다른 분포의 수익률 값들을 반환하기 시작했습니다


어느정도 단계를 지나가서는
확률 분포에 기반하여 데이터들을 생성하다 보니 테스트 데이터의 생성 수익률이 예측의 효과를 어느 정도 내긴 하지만
손실함수를 간단하게 조작하고, 경량화된 모델을 사용해서인지,
복잡한 시장의 케이스를 모두 예측하지는 못한다는 걸 마지막 차트를 보며 알 수 있었습니다.
앞으로는 이 합성데이터 생성모델을 여러 자산별로 학습시켜서
무한한 데이터 생성을 위한 모델로 사용할 예정입니다.
무한한 데이터 생성은 해당 자산 강화학습 트레이딩 모델이 마음껏 훈련할 수 있는 환경을 제공해 주고
임의의 행동을 취했을 때, 해당 자산의 확률적 보상을 학습할 수 있도록 Offline RL을 위한 데이터들을 무한히 만들어줄 겁니다.
그리고 확률적으로 훈련된 트레이딩 모델들을 검증하고 여러분들이 접하고 계시는 JeTech Lab에
조만간 출시될 유료 회원들에게만 제공을 해줄까 합니다.
합성데이터들을 무한히 만들어낼 수 있기 때문에
간혹 연락을 주시는 대표님들 합성데이터와 훈련데이터셋에 관심이 있고 수요가 있다면
합성 데이터도 가공해서 판매를 해볼까 생각 중이기도 합니다.
심심해서 이런저런 논문들을 살펴보고 가지고 놀아봤는데
상용화를 위한 개발을 진행해도 좋겠다는 생각이 들어서 좋았고
꾸준히 새로운 지식을 탐구해야 하는 이유를 오늘 다시 한번 다지게 되기도 했습니다.
오늘 다룬 내용은 더 연구하고 가다듬어서 상용화를 위해 노력하겠습니다.
감사합니다.