안녕하세요.
지난번 Decision Transformer에 기반한 TradingGPT 모델을 만들고
트레이딩을 할 수 있도록 학습하는 방안에 대해서 개요를 이야기했었습니다.
이번 포스트에서는 Trading GPT를 pretrain 하고
학습된 모델이 트레이딩을 수행했을 때 어느정도 성과를 낼 수 있는지 분석해보려고 합니다.
Gymnasium based Crypto Environment
처음으로 필요한 것들은 GPT 모델이 강화학습을 진행하는 동안
상호작용하기 위한 환경을 구성합니다.
OpenAI에서 관리하던 gym 프로젝트를 포크 하여
커뮤니티 기반으로 관리되는 연구자와 개발자들이 강화학습 알고리즘을 실험하고 벤치마크 할 수 있는
표준화된 인터페이스를 제공합니다.
Gymnasium Documentation
A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
gymnasium.farama.org
공식문서를 통해 gymnasium.env 클래스를 상속받아
crypto 트레이딩에 적합한 CryptoEnv 클래스를 구현했습니다.

핵심적으로 구현해야 하는 함수들은 step(), reset() 등이 있습니다.
step 함수는 에이전트가 취한 행동에 대한 환경의 반응을 업데이트하고
다음 상태, 보상, 에피소드 종료 여부, 부가정보들을 반환하도록 구현합니다.
함수구현 이후, 이 환경에서 에이전트가 취할 수 있는 행동을 action_space에 기반해서 구현합니다.
TradingGPT가 환경에서 -1 ~ 1 사이의 실수를 취할 수 있도록 설정해 주었습니다.
그리고 매 step 마다 모델이 포지션진입을 위해 관찰하는 데이터를 observation_space로 정의해 주었고
이번 실험에서는 100 timesteps 비트코인 차트데이터를 제공해 주었습니다.
import gymnasium as gym
class CryptoEnv(gym.Env):
def __init__(self, data, state_dim, features):
...
self.action_space = gym.spaces.Box(low=-1, high=1, shape=(1, 1), dtype=nplfloat32)
self.observation_space =gym.spaces.Box(low=-np.inf, high=np.inf, shape=(state_dim, features))
...
구현한 step 함수에 대해 조금 부연설명을 하자면
지난번 이야기한 것처럼
트레이딩 분야의 강화학습 환경은 특이하게도
모델이 환경에서 상호작용하지만 그 크기나 반응, 모델의 행동을 가한다고 환경이 변화할 정도의 영향도가 미비합니다.
그래서 트레이딩환경에서는 모델이 환경에 영향을 많이 주지 않습니다.
대신 어떤 행동(포지션)을 취했을 때, 시장이 어떻게 흘러갔고
보상(수익)이 어떻게 제공될지 반환할 수 있습니다.
(과거 데이터로부터 trajectory 데이터를 만들어내고 학습하는 offline RL)
Expert Trading Trajectory Data
TradingGPT는 논문에서처럼 expert trajectory data에 기반해서 학습을 진행했습니다.
expert trajectory data라는 건 여기선 트레이딩 환경에서 큰 보상을 얻어낸 일련의 행동데이터들을 보면서 학습하는 것입니다.
가장 확실한 방법으로, 트레이딩을 잘하는 사람들을 찾아가서 이 시점에 어떤 매매를 했을지 물어볼 수 있으나
AI가 학습하는 데이터로 변환하기도 어려운 단점이 있습니다.
추후 다양한 트레이더들과 협업하면서 expert trajectory data를 만들어내는 툴을 만들 예정입니다.
다양한 트레이딩 방법을 구사하는 트레이더들을 만나고 협업하고 서비스화할 예정입니다.
그런데 생각해 보면, 다른 분야는 전문가들에 의존해서만 expert 수준의 데이터를 얻을 수 있지만
트레이딩 분야에선 과거차트에서 이때 사고 이때 팔면 되겠다는 정도는 초등학생도 알 수 있습니다.
그래서 위와 같은 방법을 이용하여 expert trajectory data를 만들 수 있습니다.
이 expert는 미래에서 왔기 때문에 진입하는 모든 포지션이 수익으로 이루어지는 전설의 트레이더입니다.

물론 이런 데이터를 사용하면 모델이 학습하면서
고차원 영역의 트레이딩 영역에서 최적해를 곧잘 집어내는 데이터이기 때문에
아무리 AI라고 한들 그 상관성을 잘 파악해내지 못할 것 같다고 생각했습니다.
이를 방지하기 위해 expert-0.2~0.5 수준의 데이터로 조정을 해주었습니다.
이 정도만 해도 매일 오를지 내릴지는 맞추고
움직인 가격의 20~50%를 매일 얻어낸다는 것이니 엄청난 트레이더입니다.
(나중에 고도화하면서는 이런 expert들이 상황에 일정 확률로 랜덤 하게 행동하도록 데이터를 변형해 주면
상태공간에서 더 많은 exploration을 할 수 있도록 학습데이터를 조정해 줄 수 있습니다. )
Trading GPT (based on GPT2-small)
다음은 본격적으로 트레이딩을 수행할 TradingGPT 모델을 만드는 부분입니다.
공식 논문에서 사용한 에이전트 모델도 GPT2 기반의 모델인데
저도 첫 실험으로 시도해 보는 것이다 GPT2-small 수준으로 모델을 구성했습니다.
GPT2-small 모들은 768개의 embedding dimension, 12-attention head, 12 transformer block으로 구성되어 있습니다.
하지만 언어모델에서의 GPT는 vocab_size가 50,257이지만,
실수데이터를 사용하는 TradingGPT에서는 이를 단순히 1로 설정했다는 점이 다르고
positional encoding 같은 episode cotnext size 1024였으나 100시간 데이터로 조정을 해주었다는 점이 다릅니다.


그래서 대략 파악해 보면 GPT2-small 수준에는 못 미치는 대략 97M 정도의 파라미터를 가질 것으로 판단됩니다.

GPT2 Extra Large는 15억, GPT3는 1750억, GPT4는 비공개이지만
지수적 상승이 있었음을 예상할 수 있습니다.
현존 언어모델들보다는 파라미터 수가 적고, 수년 전 발표된 수준의 모델 파라미터를 갖고 있지만
이 정도도 일반 cpu로는 학습시키기 아주 어렵습니다.
Training 과정과 모델 성능 점검 리뷰
TradingGPT 수준 모델은 A100, V100 등의 GPU를 통해서 학습을 진행했습니다.
모델을 학습하는 과정은 Decision Transforme의 Trainer 구현부를 응용했습니다.
간단히 이야기하자면, expert trajectory 데이터상의 현재 진입해야 할 포지션과
모델이 생각하는 포지션을 비교하여 손실함수를 정의해
파라미터들이 업데이트되도록 학습을 진행했습니다.
아마 제 채널을 보시는 분들은 이런 학습의 원리, 수리통계적 내용은 알고 있거나,
알고 싶지 않으실 것 같아 생략하고, 저보다 더 잘 설명해 주시는 블로그나 유튜브들이 많으니 참고 바랍니다.
학습을 진행하면서, evaluation 데이터셋을 구분해 두었고,
해당 데이터를 여러 구간으로 나누어 에피소드들로 지정했습니다. (에피소드별로 대략 100일의 기간)
학습을 마치고 온 모델을 evaluation 데이터셋에서 트레이딩 시켜보고 수익률을 모니터링했습니다.




위 왼쪽 각 에피소드에서 모델들이 트레이딩을 진행하며 얻은 수익률을 보여주고 있고
오른쪽은 해당 모델들의 에피소드 수익률의 평균치를 보여주고 있습니다.
(아래 두 차트는 action_error, train_loss_mean)
에피소드들의 테스트 트레이딩 평균치데이터도 우상향 하는 듯하다가 0에 수렴하는 것을 보니
에피소드 구간별 최적 트레이딩 방법은 모델이 학습하지 못했음을 알 수 있습니다.
하지만 첫 사진을 확인해 보면 의아한 것이 특정 에피소드들은 아주 정석적인 강화학습 보상함수의 우상향 하는 그래프가 만들어지는데
다른 에피소드들은 그렇지 않은 것을 볼 수 있습니다.
다시, 가장 높은 수익을 낸 에피소드: 파란 선, 가장 낮은 수익을 낸 에피소드: 초록
그리고 각 에피소드들의 buy-and-hold 수익률 : 각각 주황, 빨간 선으로 나타내어 보았습니다.
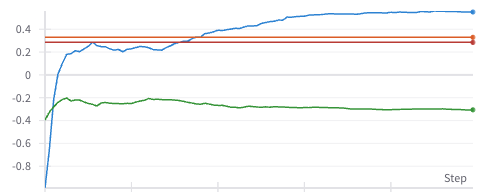
모델이 파란 에피소드에서는 결국 단순 매수포지션보다 우위의 성과를 낼 수 있었고
초록에피소드 구간에서는 그러지 못했습니다.
저는 이 결과를 보고 제가 가지고 있던 투자관점, 철학 등을 이번기회에 과학 연구방법으로 검증할 수 있겠다고 생각했습니다.
몇 년 전부터 저를 알아오셨던 분은 제가 레이달리오의 올웨더 전략에 영향을 많이 받았음을 아실 수 있을 겁니다.
그래서 자산배분에 기반한 투자를 하고, 트레이딩에서도 상관성이 낮은 여러 전략들의 시너지가
적은 MDD를 가질 수 있음을 보여왔습니다.
트레이딩에서 어떠한 전략이던 수익을 보는 구간과 그렇지 않은 구간이 있습니다. 시장은 늘 움직이고 변화하기 때문입니다.
지금 훈련된 모델의 수익률 그래프를 보면 같은 모델이지만 특정 구간에선 수익을, 다른 구간에선 그렇지 못한 모습을 보이고 있습니다.
다른 트레이딩 전략들처럼말이죠.
모델이 모든 에피소드 구간마다 매수포지션 이상의 수익을 얻어낸다면 좋으나
그러려면 복잡도가 언어영역보다 높고 애초에 최적해를 찾는 것이 불가능에 가까운 트레이딩 영역에서 GPT4를 능가하는
파라미터를 유지하면서 학습비용을 견뎌내며 모델을 만드는 게 의미가 있을지 생각해 봅니다.
그리고 최적해를 찾아내더라도 그로 인해 시장은 변하고 의미가 없어지게 됩니다.
저는 특정 구간에 강점을 가지는 모델들을 만들어내고,
(특정 구간 우세 + 다른 구간의 수익들의 합도 평균치가 높고, 분산이 적으면 좋겠죠)
그런 모델들의 모임인 모델군을 형성해서 모델군의 추론에 기반해 트레이딩을 진행시키고
모델군의 수익그래프에서 수익이 낮은 구간을 강화시켜 줄 모델을 학습시키는 것도 가능할 것 같습니다.
그러면 상관성이 낮은 모델들을 계속해서 모아나갈 수 있습니다.
자산배분이 상관성이 낮은 자산들을 모아가는 것과 비슷한 맥락을 가지는 것처럼 보입니다.
이 과정을 반복하면 expert 까지는 아니더라도 많은 MDD를 낮출 수 있을 것으로 기대합니다.
이 부분은 앞으로 많은 시간 동안 연구자답게
제가 가지고 있는 투자관점과 철학에 대해 귀무/대립가설을 설정해서 검증해 보는 시간을 갖도록 하겠습니다.
TODO
결국 제가 이 모델들을 제공하는 JeTech Lab에 데이터들을 무료로 공개하기로 했었습니다.
제가 미래에 구현할 부가적인 기능들과, 만나서 이야기했던 대표님들과의 협업을 위해 일부 모델만 공개할 예정입니다.
제가 모델을 공개할 수 있는 이유는, 수십, 수배각지 다양한 모델들을 모아가서 모델군을 형성할 건데
단순히 몇 개 정도의 모델의 포지션을 공개하는 것 정도는
저의 투자 메커니즘에 큰 영향이 있지 않을 것 같고
현재로서는 트레이딩 수익정도면 제가 생활하는데 충분한 보탬은 되고 있다고 생각해서
지금 당장은 재미와 보람, 이 분야에서 인지도를 확장시켜 가는 게 더 중요하다고 생각하고 있습니다.
(당장은 블로그, 유튜브 수익설정도 하지 않고/하지 않을 예정입니다)
아무튼, 오늘은 지난번 소개한 Decision Transformer에 기반한 Trading GPT를 직접 학습시키고
학습시킨 모델들의 성과를 분석해 보는 시간을 가졌습니다.
하루 30분, 1시간 정도 시간을 내서 몇 주간 구현하고 학습시키고 분석한 것들을
하루 만에 적어내고 보시느라 다 이해하셨을지 모르겠는데요.
제 블로그, 유튜브 보시는 본들은 이미 범상치 않으신 분들임을 제가 이미 알고 있어서
저의 연구가 재미로라도 느껴지셨으리라 생각해 봅니다.
앞으로도 더 다양한 연구, 데이터, 알고리즘들을 전달해 드리기 위해 노력하겠습니다.
감사합니다.
'Data & AI' 카테고리의 다른 글
| 최신 딥러닝 나스닥 가격 예측모델 (TimeLLM) (4) | 2024.05.08 |
|---|---|
| JeTech Lab에 사용될 시계열 예측 모델 소개 (TimeLLM) (0) | 2024.04.22 |
| TradingGPT (Decision Transformer: Reinforcement Learning via Sequence Modeling) (0) | 2024.03.18 |
| [JeTech Lab] 설계-2. AI 모델 배포/추론에 대한 고민 (3) | 2024.02.26 |
| [JeTech Lab] 1. 소개 (3) | 2024.02.16 |



