YouTube : https://youtu.be/_s0HQTTbfuQ
안녕하세요.
이번 시간에는 4월이 지나기도 해서 4월 주식 데이터 리뷰를 하면서 간단한 머신러닝 모델을 이용한 백테스트까지 보여드릴 예정입니다.
데이터 준비
이번에도 AWS에 월별 수입된 주식 데이터를 가져와서 데이터를 분석해 보도록 하겠습니다.
qcut_number = 50
df['train_momentum'] = df['train_momentum'].astype(float)
df['train_momentumqt'] = pd.qcut(df['train_momentum'], qcut_number, labels=False)
df['target_momentum'] = df['target_momentum'].astype(float)
df['target_momentumqt'] = pd.qcut(df['target_momentum'], qcut_number, labels=False)
df['PBR'] = df['PBR'].astype(float)
df['PBRqt'] = pd.qcut(df['PBR'], qcut_number, labels=False)
df['PER'] = df['PER'].astype(float)
df['PERqt'] = pd.qcut(df['PER'], qcut_number, labels=False)
df['ROE'] = df['ROE'].astype(float)
df['ROEqt'] = pd.qcut(df['ROE'], qcut_number, labels=False)
df['OIGR'] = df['OIGR'].astype(float)
df['OIGRqt'] = pd.qcut(df['OIGR'], qcut_number, labels=False)
df['ROA'] = df['ROA'].astype(float)
df['ROAqt'] = pd.qcut(df['ROA'], qcut_number, labels=False)
df['RR'] = df['RR'].astype(float)
df['RRqt'] = pd.qcut(df['RR'], qcut_number, labels=False)train_momentum은 3월 한 달 간한 달간 주식들의 상승률, target_momentum은 4월 한 달간 주식들의 상승률이 담겨있습니다.
그리고 그 밖에 주요 4월 메타데이터들을 준비했습니다. 4월 메타데이터, 4월까지의 모멘텀으로 4월의 수익률을 살펴보기 위해서입니다. qt가 붙은 컬럼들은 해당 컬럼의 분위를 나타내고 있습니다. 저는 50 분위를 구해서 분위 구간당 2%의 주식을 나누었습니다.
데이터 분석
가장 많이 알려진 PER, PBR 지표들과 유보율(RR), 영업이익증가율(OIGR)과 수익률 상관관계를 살펴보겠습니다.
4월 가치지표데이터들과 4월 한 달간의 수익률을 분석하기 위해 산점도를 출력해 보았습니다.
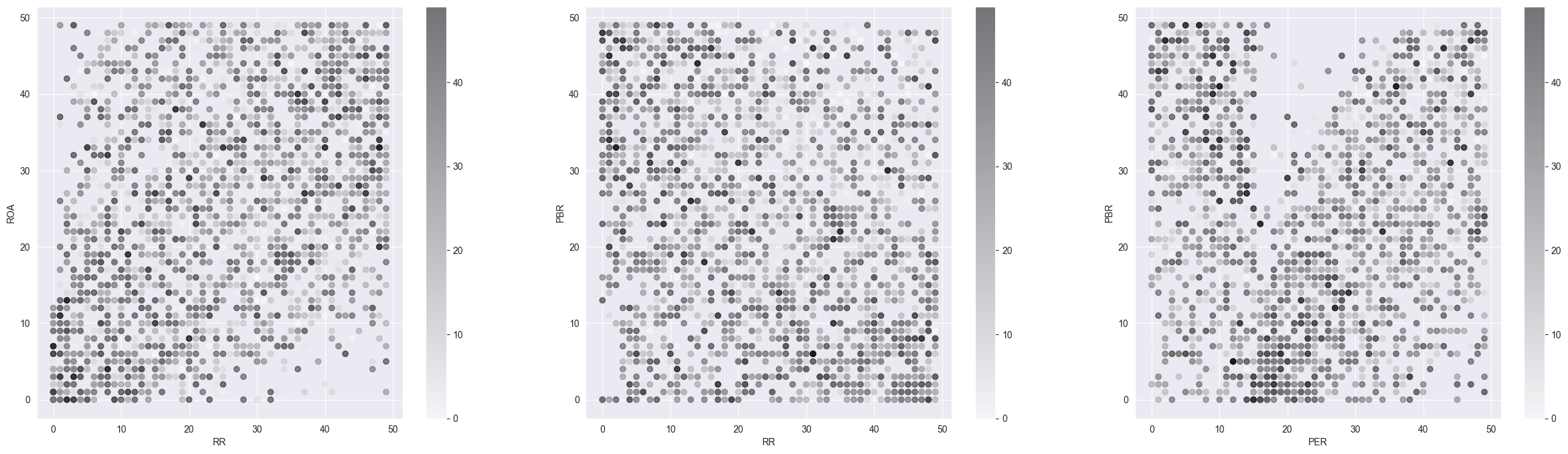
작게 보이긴 하지만 여기서 색이 진한 점들이 수익률이 좋은 주식들을 의미합니다.
우리가 가치지표들을 수집해서 저 PER, 저 PBR 외치는 것보단 이렇게 데이터들을 시각화해서 보는 것과는 느낌이 다릅니다.
우리가 여기서 살펴볼 점들은 여러 특성들을 비교하면서 데이터들을 살펴보고 곱씹어보는 게 중요합니다.
단순히 상관관계를 계산하기보다 이렇게 시각화하면 상관관계로는 나오지 않지만 인간이 보았을 때 유의미한 패턴들을 찾아낼 수 있습니다. 앞선 차트들에서 굳이 분석한 것들을 이야기해 보자면 검은 점들이 밀집한 구간들이 존재한다는 것들입니다. 혹여 색이 옅어지는 구간들을 제외하는 로직만 적용해도 평균 수익률 향상에 도움 될 것입니다.
다음은 ROA, ROE에 대해서 분석해 보았습니다.
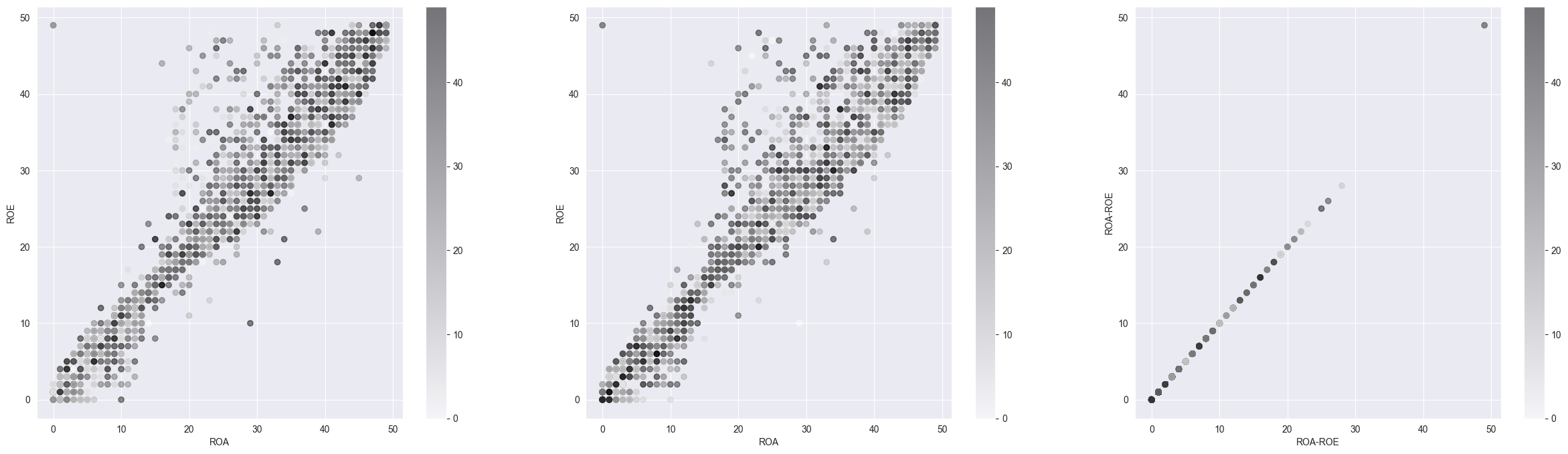
ROA, ROE를 각 축에 나타내고 3월 수익률에 대한 정도, 4월 수익률에 대한 정도를 산점도로 표시했습니다.
ROE, ROA가 각각 자본과 자산을 이용하는 정도를 나타내기 때문에 선형적인 관계를 가지고 있습니다.
선형적 관계를 가지는 특성들에서 이 선형적 특성이 벗어나는 주식들에 대해서(y=x 식에서 먼 데이터일수록) 수익이 저조한 것 같아
세 번째 차트가 f(x): y=x에 대해 이격정도를 나타내고 이 거리별 수익률을 나타내고 있습니다.
어느 정도 주기성이 있긴 하지만 선형성이 강할수록 수익이 높은 것을 볼 수 있습니다.
또 다른 특성 데이터 추출방법
오늘은 간단한 머신러닝 모델을 만들어서 백테스트를 진행할 건데
머신러닝에 어떤 특성데이터를 사용할지 고민이 될 때가 있습니다. 어느 때는 PER, PBR이 의미 있는 경우가 있고
다른 특성들이 더 의미 있게 쓰일 수 있기 때문입니다.
위와 같이 데이터를 시각화해보는 방법도 좋지만
Random Forest와 같은 앙상블 기반 결정트리 알고리즘을 이용해서 주요한 특성을 찾아내는 방법도 있습니다.
일단 주요 특성들을 가공하고 Random Forest 모델을 만들어보겠습니다.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=df['target_momentumqt'].nunique(), random_state=42)
clf.fit(df[['RRqt', 'ROAqt', 'OIGRqt', 'ROEqt', 'PERqt', 'PBRqt', 'secor_code', 'train_momentumqt']], df['target_momentumqt'])위 코드는 Random Forest Classifier를 만들고
메타데이터들을 입력으로 기대 수익률의 분위수를 분류하는 분류기 모델을 학습하는 코드입니다.
이 분류기가 여러 의사결정트리를 만들면서 모델을 분류하는데 입력받은 특성 중 어떤 특성이 도움이 되는지 정도를 찾아볼 수 있습니다.
fig, axes = plt.subplots(figsize=(9, 5))
axes.bar(index, clf.feature_importances_ - clf.feature_importances_.mean(), tick_label=df[['RRqt', 'ROAqt', 'OIGRqt', 'ROEqt', 'PERqt', 'PBRqt', 'sector_code', 'momentum_3']].columns)
axes.set_title('feature importance')
axes.set_xlabel('feature')
axes.set_ylabel('feature importance')
axes.set_xticklabels(df[['RRqt', 'ROAqt', 'OIGRqt', 'ROEqt', 'PERqt', 'PBRqt', 'sector_code', 'momentum_3']].columns, rotation=45)
axes.grid()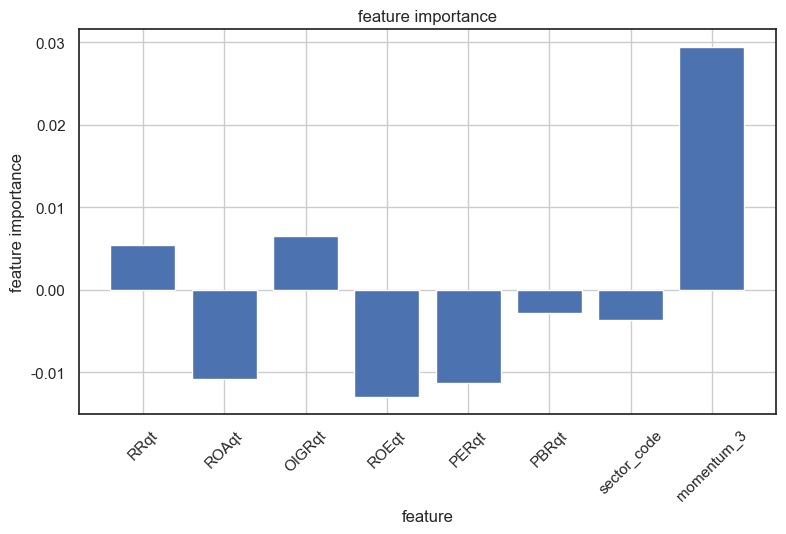
분류모델이 학습하면서 train_momentum(직전 1개월인 3월 모멘텀) 지표에 대해서 중요하게 여기고 있습니다.
수치들이 큰 차이를 보이고 있는 사례는 아니지만 우리가 직관적으로 모델이 어떻게 작성되었는지는 알기 어렵지만
해당 분류기가 수익률을 분류하는데 도움이 된 특성들을 찾아볼 수 있습니다.
SVM 모델학습과 백테스트
우리가 이렇게 특성 데이터들을 시각화해보면서 우리가 원하는 수익률을 얻는 주식데이터들이 특성공간에서 어느 위치에 있는지 찾아볼 수 있습니다. 우리가 분석을 하면서 ROA, ROE들의 상관성을 보고 RO_gap이라는 특성을 만들어내는 나름의 Feature Engineering 과정을 거치기도 하고, 앙상블 분류모델의 feature importance에서 유의미한 특성데이터를 추출해서 사용할 수도 있습니다.
오늘은 간단히 오늘 분석을 통해 얻은 데이터들로 support vector machine 모델을 만들어보겠습니다.
우리가 특성들을 좌표에 산점도로 표시해서 데이터들을 살펴보면서 수익률의 분포를 살펴보았듯, svm에서 입력받은 특성들을 특성공간에 흩뿌려 데이터를 분리해서 분류할 수 있는 Decision Boundary를 찾아내는 알고리즘입니다.
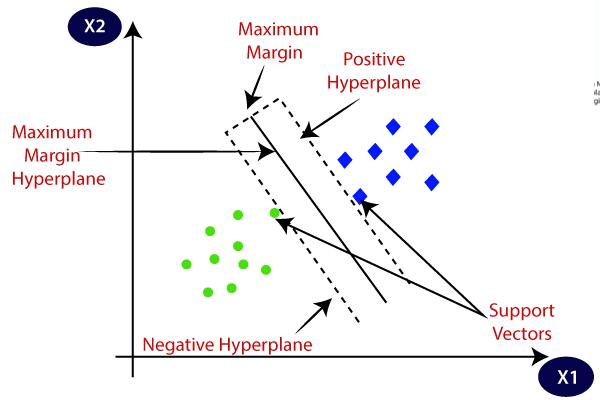
위 사진처럼 특성별로 데이터를 특성공간에 산점도로 뿌리고 해당 데이터들을 가장 잘 분류할 수 있는 결정경계를 정해서 분류를 합니다.
지금까지 2차원 영역에 데이터를 뿌려보았는데 우리가 이해할 수 있는 3차원 영역에 데이터를 뿌려보도록 하겠습니다.
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.scatter(df.PERqt, df.PBRqt, df.train_momentumqt, c=_df.target_momentumqt, cmap='binary', alpha=0.3)
ax.set_xlabel('PER')
ax.set_ylabel('PBR')
ax.set_zlabel('momentum')
fig.colorbar(ax.collections[0], ax=ax)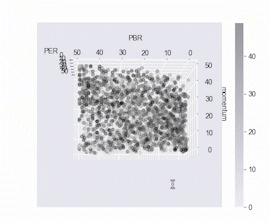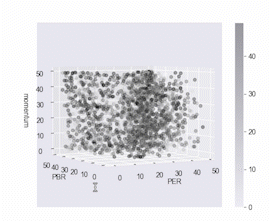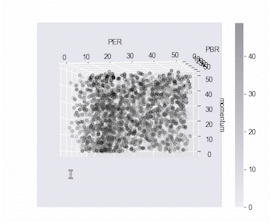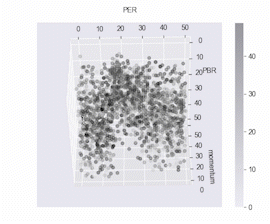
3차원 데이터에서도 마찬가지로 검은 점들이 높은 수익을 낸 주식 데이터들입니다.
하지만 우리가 특성을 3개만 사용하기엔 우리가 Feature Engineering이나 여러 분석으로 찾아낸 특성들을 사용하기 부족하겠죠
SVM에서는 여러 특성들을 고차원 특성공간에 투영시키고 해당 공간에서 결정경계를 찾아 분류를 진행합니다.
SVM에서도 결정경계를 단순한 선으로 구분할 수 있지만 특성이 여러 개일수록 고차원의 영역에서 비선형 분류를 할 수 있도록 선형 매핑을 위해 커널 함수를 사용합니다. 커널함수는 입력 데이터를 고차원 공간으로 매핑하여 문제를 풀 수 있도록 도와주는데 Radial Basis Function, Polynomial 커널등이 있습니다.
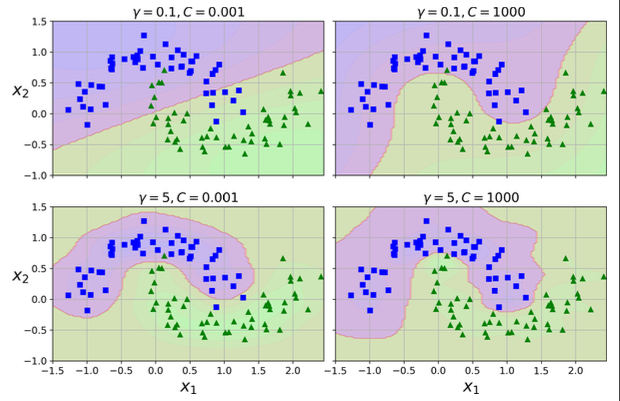
그럼 이제 3월 데이터 기준으로 Polynomial kernal SVM Classifier모델을 만들어보고
4월에 투자에 적용했을 때의 수익률을 백테스트 해보겠습니다.
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 3월 데이터로 학습
df['RO_gap'] = abs(df['ROA'] - df['ROE'])
svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly"))
])
svm_clf.fit(df[['RO_gap', 'PERqt', 'PBRqt', 'train_momentumqt']], df[['target_momentumqt']])
# 4월 데이터 조회
...
prediction_df['predict'] = svm_clf.predict(prediction_df[['RO_gap', 'PERqt', 'PBRqt', 'train_momentumqt']])우리가 찾았던 특성들을 입력으로 분류기를 학습하고
4월 데이터를 가져와 predict라는 컬럼에 담아두었습니다.
predict는 해당 주식이 모멘텀이 어느 정도로 나올지 나타낸 것으로, 클수록 기대수익률이 높다는 것을 의미합니다.
그리고 predict를 축으로 실제 target_momentum(4월 수익률)을 시각화해보았습니다.
prediction_df = prediction_df[prediction_df.target_momentum != prediction_df.target_momentum.max()]
(prediction_df.groupby('predict').agg({'target_momentum': 'mean'})-1).plot(kind='bar')
x = (prediction_df.groupby('predict').agg({'target_momentum': 'mean'})-1).index
y = (prediction_df.groupby('predict').agg({'target_momentum': 'mean'})-1).values.flatten()
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
plt.plot(x,p(x),"r--")첫 줄에 target_momentum이 가장 큰 주식 하나를 제외했는데 4월에 모멘텀 164의 에이프로젠 H&G 주식 하나가 평균을 너무 높여서
이상치 데이터 삭제를 진행해 줬습니다. (주주 여러분 축하드립니다)
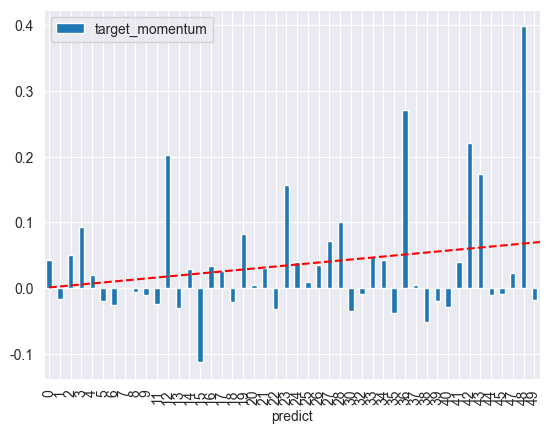
x축은 모델이 예측한 수익 기대분위, y축은 실제 수익률, 빨간 점선은 해당 데이터들의 선형 회귀선입니다.
수익 예측 모델이 예측한 값들이 기대별로 우상향함을 알 수 있습니다. 나름 괜찮은 투자를 한 것으로 보입니다.
그래서 지금 5월에 저 모델이 어떤 주식을 사라 고하는지가 궁금하시죠
제가 지금까지 보여드린 데이터 분석과 이에 기반한 모델들, 그런 모델들이 주는 시그널들도 저의 사이트 출시와 함께 제공될 수 있도록 기획하겠습니다. 혼자 개발을 하다 보니 아무래도 시간이 늦춰지고 있지만 기다려주시는 구독자분들께는 2분기 안에 무료로 제공받을 수 있도록 하겠습니다.
요즘 유명 연예인들을 필두로 하는 주가조작 뉴스로 시끄러운데 같은 분야에 몸담고 있으면서 참 안타까운 마음이 듭니다.
더 안타까운 건 투자 관련 법인, 사업자들이 대중들에게 범죄조직처럼 비치고 많은 이들이 투자활동에 점점 멀어지게 되는 것입니다.
일부 나쁜 마음을 가진 집단들로 하여금 대한민국의 경제지식이나 투자에 대한 참여도를 낮추게 하는 게 마음 아프고
투자 관련 업종자체가 본래 가지는 건설적이고 고객들에게 가치를 제공하는 기능이 잊히고 있습니다.
제가 모든 걸 개선한 금융서비스를 갖출 때까지 기다려서 많은 이들에게 제공하기보단
당장은 부족하지만 성장하는 과정을 기록하고 진심을 이야기하면 나중엔 서비스에 투자해 주시는 분들께 신뢰를 줄 수 있고 더 깊은 관계로 소통할 수 있다고 생각하기 때문입니다.
부족한 저를 구독해 주시고 지켜봐 주시는 여러분들 감사하고
다음에도 유익한 정보들 공유할 수 있도록 하겠습니다.
'AI' 카테고리의 다른 글
| 강화학습 트레이딩 3. 강화학습 (0) | 2023.08.14 |
|---|---|
| 트레이딩에 AI를 적용하기위한 준비 (0) | 2023.05.26 |
| AI 알고리즘 투자 - 몸풀기 (1) | 2023.05.03 |
| [강화학습] 3. 강화학습의 의사결정과정 (0) | 2023.02.24 |
| [강화학습] 2. 강화학습은 인생이다. (0) | 2023.02.20 |



